Enable custom search with Apache Solr and Carrot C2
Curated Collections of Documents.
One of the tasks I undertake in my own projects and in research is that of undertaking a literature review. As a side effect I collect many documents that I scour through and use as reference material. Generally I use my google drive account and a directory structure to organise these documents. The directory structure, in the general case, is arranged where the top level directory is the most general category I might be interested in, such as “Math” and subdirectories each form subtopics, such as “differential_equations”, “functions” and “game_theory” for example. By doing this, a curated collection of documents emerges somewhat organically over time. And often the documents are consumed by taking notes within the context of a project, referenced in writing or program comments, or simply read but not necessarily used. While the resulting collection may rely on my own memory to know where I have stored this information previously, it is still useful to be able to search the pdf documents for various topics that I have already collected, using the search function within macOS finder for example.
An Opportunity
However, wouldn’t it be great if there were other ways of surfacing information contained in the documents that I had collected? Tools such as clustering may enable me to identify documents that contain related topics, that I had not previously envisioned.
Enabling Tools
It is worth exploring existing tools that may contribute to achieving this aim, and as such I had in the past been aware of Apache Solr as a search engine, and had thought this may be useful, for example, in indexing and searching the large repository of software requirements and specifications at work. However, the same tool could just as easily be applied to other projects, such as research and learning in my spare time. The documentation for Apache Solr also indicated that search results could also be clustered dynamically, using an open source project Carrot2.
In order to import collections of documents, I made use of the solr java api and wrote a small utility that traverses a given directory and filter, in order to load the files along with some custom attributes, into the solr instance (defined in a configuration file specified as part of the command arguments), this project is located at:
After some experimentation, the combination of these tools allow for a custom search interface and support of dynamic clustering for search query results, an example screenshot of one of my document collections under the topic “Math” is shown below.
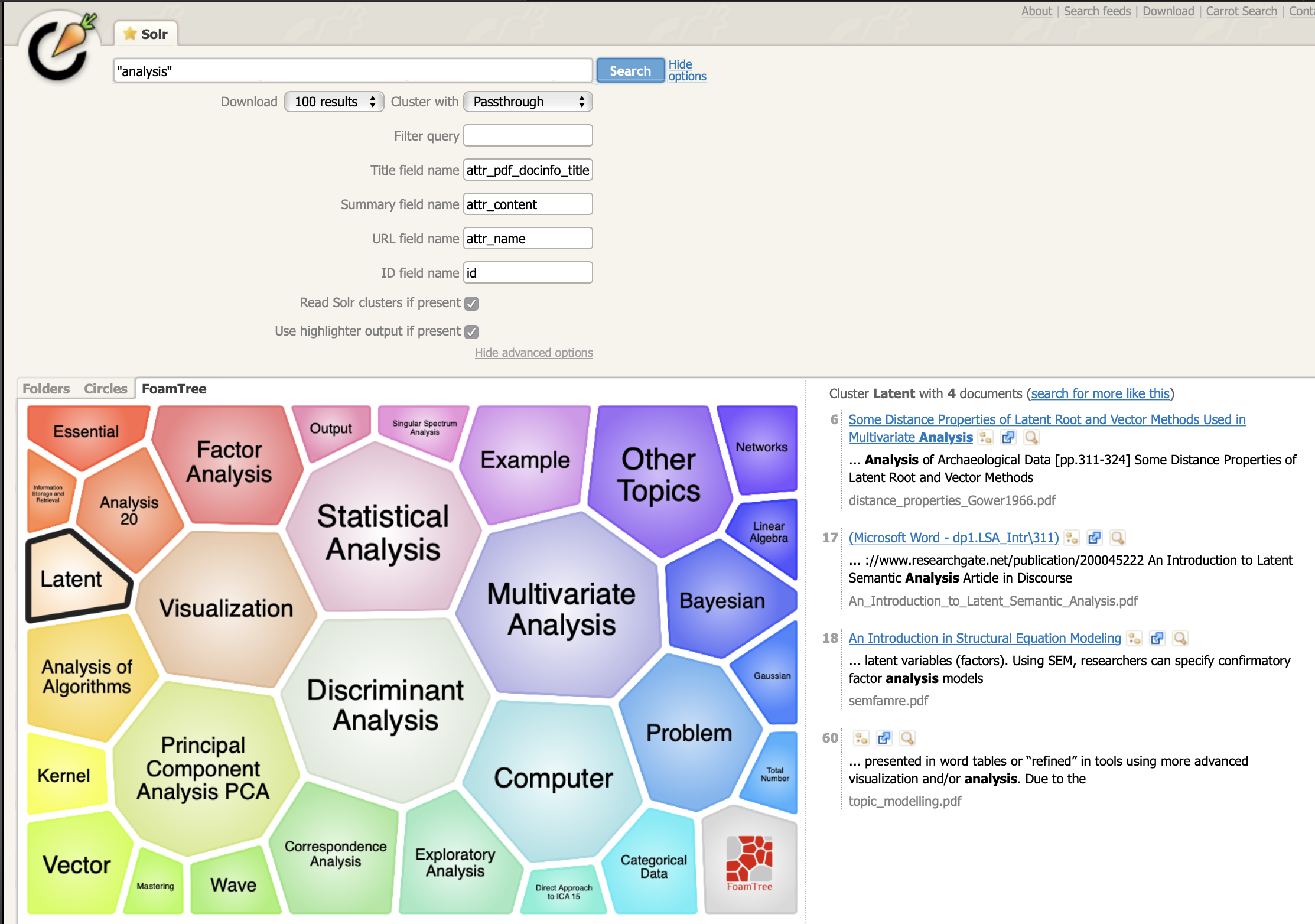
The Experiment
Given the availability of these tools, and the convenient distribution of apache solr within docker, it was possible to prepare an environment and configuration that would support the above aim. The architecture of the approach is described in the Carrot2 Solr integration notes. The integration document provides all of the required instructions to successfully configure the two components to achieve my goal, however, some of the information on configuration will be repeated here.
Configuring the Docker images.
In order to host the carrot web application, I am using tomcat which will run in a separate container, and reference an external webapps volume. The apache solr docker image will mount an external data volume to permit customisation of the solrconfig.xml file to enable the carrot2 functionality.
The war file that was leveraged for the carrot2 web application is located at:
https://get.carrot2.org/head/latest/
The filename itself is carrot2-webapp-3.17.0-SNAPSHOT.war, that can be downloaded and stored for later.
Configuring Apache Solr.
The following example docker-compose.yaml file listing illustrates the configuration of the apache solr instance. Documentation on the solr docker image is available at the docker-solr project on github.
version: '3'
services:
solr:
image: solr:8
ports:
- "8983:8983"
volumes:
- /mypath/apache_solr/data:/var/solr
command:
- solr-precreate
- gettingstarted
environment:
- SOLR_HEAP=4g
volumes:
data:
In this example, /mypath/apache_solr/data is the host machines mount point, for the data directory within the container (/var/solr). When new cores are created their folders for data and configuration will be located at that path. The java heapsize is also increased slightly, to permit some of the larger collections I am working with.
For experimentation this is run with docker compose within the same directory as the docker-compose.yaml file, for example (it can later be modified to run in docker swarm along with the other tomcat component with a shared network):
docker-compose up -d
Once loaded, it is possible to experiment with the “gettingstarted” core to import data and explore the usage of the post tool, the documentation of the Apache Solr project contains how to get started in general.
To use the tools within the solr container, launch an interactive session within the container such as:
docker exec -it compose_solr_1 "/bin/bash"
In the case of this example a new core named “research” is created by the command:
bin/solr create -c research -s 1 -rf 1
Note that this deployment is not clustered, so I’ve only used 1 shard and 1 replica in the above example. But of course other deployment configurations are possible, and the docker-solr project provides plenty of details as does the Apache Solr documentation for more highly available deployment modes.
The default solrconfig.xml needs to be customised in order to enable importing word or pdf documents via the Tika library, as well as customisations required for the carrot2 integration within solr.
Alterations to solrconfig.xml
The folder at /mypath/apache_solr/data contains the directory for our example “core” named “research” (data/research). Configuration of the core is located within the subdirectory conf.
The first step is to enable the loading of the additional libraries included in solr, these are added below the “luceneMatchVersion” element.
<lib dir="${solr.install.dir:../../../..}/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-cell-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-clustering-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-langid-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/velocity/lib" regex=".*\.jar" />
<!-- browse-resources must come before solr-velocity JAR in order to override localized resources -->
<lib path="${solr.install.dir:../../../..}/example/files/browse-resources"/>
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-velocity-\d.*\.jar" />
In order to enable the pdf and word document extraction a requestHandler is added below the /query request handler for the path /update/extract as follows:
<!-- Solr Cell Update Request Handler
http://wiki.apache.org/solr/ExtractingRequestHandler
-->
<requestHandler name="/update/extract"
startup="lazy"
class="solr.extraction.ExtractingRequestHandler" >
<lst name="defaults">
<str name="xpath">/xhtml:html/xhtml:body/descendant:node()</str>
<str name="capture">content</str>
<str name="fmap.meta">attr_meta_</str>
<str name="uprefix">attr_</str>
<str name="lowernames">true</str>
</lst>
</requestHandler>
In order to enable the Carrot2 integration, the searchComponent for the clustering algorithm is added.
<!-- clustering search
-->
<searchComponent name="clustering" class="solr.clustering.ClusteringComponent">
<!-- Lingo clustering algorithm -->
<lst name="engine">
<str name="name">lingo</str>
<str name="carrot.algorithm">org.carrot2.clustering.lingo.LingoClusteringAlgorithm</str>
</lst>
<!-- An example definition for the STC clustering algorithm.
<lst name="engine">
<str name="name">stc</str>
<str name="carrot.algorithm">org.carrot2.clustering.stc.STCClusteringAlgorithm</str>
</lst>
-->
</searchComponent>
And a corresponding request handler is added to the configuration that references the imported fields of the documents. In this case I am working with pdf documents only. However, if working with word, review the attributes resulting from word import documents for the document title.
<!-- search handler to support clustering queries from carrot war file -->
<requestHandler name="/config2_2" class="solr.SearchHandler">
<lst name="defaults">
<str name="defType">edismax</str>
<str name="qf">
attr_pdf_docinfo_title^1.5 attr_content^1.0
</str>
<str name="rows">100</str>
<str name="fl">id,attr_name,attr_pdf_docinfo_title,attr_created,attr_meta_author,attr_categories,attr_fileurl,score</str>
<str name="df">attr_content</str>
<!-- default output as xml for carrot2 search interface. -->
<str name="wt">xml</str>
<!-- Enable highlighter for the content field -->
<bool name="hl">true</bool>
<str name="hl.fl">attr_content</str>
<!-- Disable highlight wrapping. -->
<str name="hl.simple.pre"><!-- --></str>
<str name="hl.simple.post"><!-- --></str>
<str name="f.content.hl.snippets">3</str> <!-- max 3 snippets of 200 chars. -->
<str name="f.content.hl.fragsize">200</str>
<bool name="clustering">true</bool>
<bool name="clustering.results">true</bool>
<str name="clustering.engine">default</str>
<!-- field mapping -->
<str name="carrot.url">attr_fileurl</str>
<str name="carrot.title">attr_pdf_docinfo_title</str>
<str name="carrot.snippet">attr_content</str>
<!-- enable clustering on highlighted fragments only. -->
<str name="carrot.produceSummary">true</str>
<!-- take a max. of 3 fragments from each document's match. -->
<str name="carrot.summarySnippets">3</str>
</lst>
<arr name="last-components">
<str>clustering</str>
</arr>
</requestHandler>
The custom fields of interest are:
- id
This is the MD5 hash of file contents created by the import utility (see the github project above) so that even if multiple copies of the same file are stored beneath the source directory tree, only one copy of that file will be imported.
- attr_fileurl
This is the fullpath to the file on disk (currently all files are served from disk in my configuration) created by the import utility.
- attr_name
Returned in the query results, this is the short filename and is created by the import utility.
- attr_categories
This is also created by the custom import utility, and is the name of the parent directory from the source directory tree, it serves as a category for the manually curated set of documents.
The Carrot2 Solr integration notes describe these configurations in more detail.
The docker container for apache solr needs to be restarted after making these changes.
Importing content into the repository.
Content can be achieved by using the utility Project: au.id.cxd.solr.utils.
The details of its configuration are described on that projects webpage, and once built can be invoked in the manner:
bin/au-id-cxd-solr-utils -s /pathto/directory/tree/to/import -c ./customsolr.conf
The customsolr.conf defines the target host and core that will receive the new files, as well as the filter to use to select files from the source directory, and the content type of those files.
solr {
host: "http://localhost:8983/solr",
core: "research",
connectTimeout:10000,
socketTimeout:60000,
filter: "**/*.pdf",
contentType: "application/pdf"
}
See the project site link for more details. However once completed you can visit the core in the solr administration and perform a test query to confirm the documents are imported.
Deploying the carrot2 webapp in Tomcat.
In order to host the carrot2 webapp, I use the tomcat docker image, and define a docker-compose.yaml file as follows:
version: '3'
services:
tomcat:
image: tomcat:jdk8
ports:
- "8080:8080"
volumes:
- /mypath/apache_solr/tomcat/webapps:/usr/local/tomcat/webapps
Then it is possible to deploy the war file into the webapps folder on the hostmachine and tomcat will automatically extract it. Once extracted, some customisation of the web application configuration is required. These are located in the path carrot2-webapp-3.17.0-SNAPSHOT/suites.
The files of interest are
- suite-webapp.xml This file will include additional configurations to permit separate definitions of search endpoints, hence it is possible to have multiple collections that can be searched defined in subsequent “suite” configuration files.
The example listing for this file is shown below (note the default sources have been removed from the file and the custom source has been added).
<component-suite>
<components>
<component component-class="org.carrot2.webapp.filter.QueryWordHighlighter"
id="org.carrot2.webapp.filter.QueryWordHighlighter"
attribute-sets-resource="component-query-highlighter-attributes.xml">
<label>Query Highlighter</label>
<title>Webapp in-document Query Highlighter component</title>
</component>
</components>
<!-- Search engines. -->
<include suite="source-local-solr.xml" />
<!-- Algorithms for webapp side clustering -->
<include suite="algorithm-lingo.xml" />
<include suite="algorithm-stc.xml" />
<include suite="algorithm-kmeans.xml" />
<include suite="algorithm-synthetic.xml" />
</component-suite>
And two new files to be created:
- source-local-solr.xml This file defines the source for the custom collection of documents defined in the solr engine as configured above. The contents of this file is shown below, it provides a description, as well as some example queries, but more importantly it includes the referenced attributes file.
<component-suite>
<sources>
<source component-class="org.carrot2.source.solr.SolrDocumentSource"
id="solr"
attribute-sets-resource="source-local-solr-attributes.xml">
<label>Solr</label>
<title>Solr Search Engine</title>
<icon-path>icons/solr.png</icon-path>
<mnemonic>s</mnemonic>
<description>Solr document source queries for the "research" solr core.</description>
<example-queries>
<example-query>equation</example-query>
<example-query>wavelet</example-query>
<example-query>distribution</example-query>
</example-queries>
</source>
</sources>
<!-- Algorithms -->
<include suite="algorithm-passthrough.xml"></include>
</component-suite>
- source-local-solr-attributes.xml This file defines the url of the solr endpoint as well as the specific attributes that will be used in displaying search results and performing clustering. The listing used in this example is shown below:
<attribute-sets default="overridden-attributes">
<attribute-set id="overridden-attributes">
<value-set>
<label>overridden-attributes</label>
<attribute key="SolrDocumentSource.serviceUrlBase">
<value value="http://solr:8983/solr/research/config2_2"/>
</attribute>
<attribute key="SolrDocumentSource.solrSummaryFieldName">
<value value="attr_content"/>
</attribute>
<attribute key="SolrDocumentSource.solrTitleFieldName">
<value value="attr_pdf_docinfo_title"/>
</attribute>
<attribute key="SolrDocumentSource.solrUrlFieldName">
<value value="attr_fileurl"/>
</attribute>
<!-- Proxy clusters from Solr. Link on 'name' field. -->
<attribute key="SolrDocumentSource.solrIdFieldName">
<value value="id"/>
</attribute>
<attribute key="SolrDocumentSource.readClusters">
<value value="true"/>
</attribute>
</value-set>
</attribute-set>
</attribute-sets>
Note the SolrDocumentSource.serviceUrlBase can use the service name when deploying both services in one docker-compose.yaml file. Otherwise, it may need to reference the ip of the host machine. Alternately if using swarm define a shared network in each separate docker-compose.yaml file and reference the service name. Note also the endpoint refers to the
The other field names are those fields returned from the corresponding requestHandler defined in the solr host for the configuration of the “core”.
After defining these configurations it should be a matter of restarting the tomcat instance and opening the url (change hostname to suite your environment):
http://localhost:8080/carrot2-webapp-3.17.0-SNAPSHOT/
In order to perform queries and dynamic clustering of search results.
Wrapping Up
It was desirable for me to be able to search multiple curated collections of pdf documents, in a manner that allows me to leverage these collections in my current practice. This is facilitated by the use of the open source projects Apache Solr and the search interface provided by the Carrot2 project. In addition the Carrot2 project provides dynamic clustering of search results, which is an opportunity for content discovery of related material within the curated collection of documents. The source index of the apache solr cluster can be organised with the addition of custom attributes, and this is readily achieved through the use of the Solr java API when importing documents.